
یادگیری عمیق چیست ؟
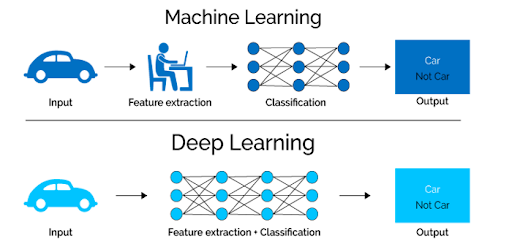
یادگیری عمیق زیرمجموعهای از یادگیری ماشین است که از شبکههای عصبی چندلایه، به نام شبکههای عصبی عمیق بهره میبرد. این شبکه ها برای شبیه سازی قدرت تصمیم گیری مغز انسان در پیچیده ترین حالت خود، طراحی شده اند. تفاوت اصلی بین یاد گیری عمیق و یادگیری ماشین در ساختار معماری شبکه عصبی آن است.
یادگیری عمیق یکی از جنبه های علم داده است که اتوماسیون را بهبود میبخشند و وظایف تحلیلی و فیزیکی را بدون دخالت انسان انجام میدهند. این امر بسیاری از محصولات و خدمات روزمره مانند دستیاران دیجیتال، کنترلهای صوتی ، تشخیص تقلب در کارتهای اعتباری، خودروهای خودران و هوش مصنوعی مولد را به وجود می آورد.
مدلهای یادگیری ماشین قدیمی موسوم به “غیرعمیق” از شبکه های عصبی ساده با یک یا دو لایه محاسباتی استفاده میکردند ولی یادگیری عمیق جدید از سه تا بیش از هزاران لایه برای آموزش مدل ها استفاده میکند.
یادگیری تحت نظارت مدلی است که نیاز به داده های برچسب خورده و ساختار مند دارد تا خروجی های دقیق ایجاد کند، مدل های یادگیری عمیق می توانند از یادگیری بدون نظارت نیز بهره مند شوند.
با یادگیری بدون نظارت، مدلهای یادگیری عمیق میتوانند ویژگیها، خصوصیات و روابطی را که برای تولید خروجیهای دقیق نیاز دارند، بدون دخالت انسان استخراج کنند. بعلاوه این مدل ها توانایی بهینه سازی و تکامل خروجی ها را برای رسیدن به نتیجه دقیق تر را دارند.
یادگیری عمیق چگونه کار میکند ؟
شبکههای عصبی مصنوعی، تلاش میکنند تا از طریق ترکیبی از ورودیهای داده، وزنها و بایاس ها که همگی مانند نورونهای سیلیکونی عمل میکنند ، عملکرد مغز انسان را تقلید کنند. این عناصر با هم کار میکنند تا اطلاعات داخلی مجموعه دادهها را به طور دقیق ،تشخیص ،طبقه بندی و توصیف کنند.
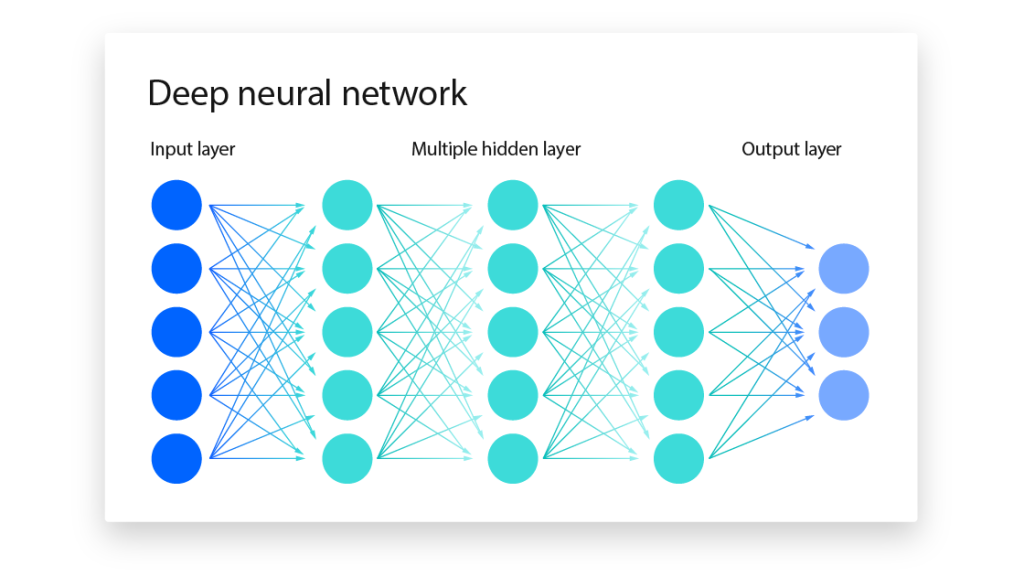
شبکههای عصبی عمیق از لایههای متعددی از گرههای به هم پیوسته تشکیل شده اند که هر لایه بر روی لایه قبلی بنا شده است.
لایههای ورودی و خروجی یک شبکه عصبی عمیق، لایههای “قابل مشاهده” نامیده میشوند. لایه ورودی جایی است که الگوریتم دادهها را برای پردازش دریافت میکند و لایه خروجی جایی است که پیش بینی یا طبقه بندی نهایی انجام میشود. ولی لایه های مابین این ها “لایه های مخفی” نامیده میشوند که اصل عملیات محاسبه، مدل سازی و تطبیق در این لایه ها اتفاق می افتد.
یادگیری عمیق به قدرت محاسباتی فوقالعادهای نیاز دارد. GPU های قوی ابزاری ایده آل برای این محاسبات هستند زیرا میتوانند به کمک فناوری جدید موسوم به تنسور، حجم زیادی از محاسبات را در هستههای چندگانه با حافظه فراوان انجام دهند. البته تامین چندین GPU در یک جا نیاز به منابع بسیار مالی فراوانی دارد. برای نیازهای نرمافزاری، اکثر برنامههای یادگیری عمیق با یکی از این سه نرم افزار کد گذاری میشوند:
JAX، PyTorch یا TensorFlow.
انواع مدل های یاد گیری عمیق
الگوریتمهای یادگیری عمیق فوقالعاده پیچیده هستند و انواع مختلفی از شبکههای عصبی برای رسیدگی به مجموعه دادههای خاص دارا هستند .در اینجا چند مدل از این الگوریتم ها را بررسی میکنیم که هر کدام مزیت های منحصر به فرد خود را دارند و نسبت به یکدیگر متفاوت هستند :
CNN(Convolutional neural networks)
در بینایی کامپیوتری و برنامههای طبقه بندی تصویر استفاده میشوند.این الگوریتم میتواند ویژگیها و الگوها را در تصاویر و ویدیوها تشخیص دهد و کارهایی مانند تشخیص اشیا، تصویر، الگو و چهره را امکان پذیر سازد. این شبکهها از اصول جبر خطی، به ویژه ضرب ماتریسی، برای شناسایی الگوهای درون یک تصویر استفاده میکنند.
CNN ها نوعی خاص از شبکه های عصبی مصنوعی هستند که از چند لایه متشکل از گره ها را تشکیل شده اند. یک لایه ورودی، دو یا چند لایه پنهان و یک لایه خروجی دارند.
هر گره به گره دیگری متصل میشود و دارای دو مولفه اصلی است : یک وزن و یک آستانه ورودی. اگر خروجی هر گره بالاتر از مقدار آستانه مشخص شده باشد، آن گره فعال میشود و دادهها را به لایه بعدی شبکه ارسال میکند. در غیر این صورت، هیچ دادهای به لایه بعدی شبکه منتقل نمیشود.
حداقل سه نوع لایه اصلی، یک CNN را تشکیل میدهند: یک لایه convolutional، لایه pooling و لایه کاملا متصل (Fully Connected). برای کاربردهای پیچیده، یک CNN ممکن است تا هزاران لایه داشته باشد که هر لایه بر روی لایههای قبلی ساخته میشود. با تولید و باز سازی داده های ورودی ، الگوهای دقیقی نمایان میشوند، با هر لایه، پیچیدگی CNN افزایش می یابد و بخشهای بیشتری از تصویر را شناسایی میکند.
لایههای اولیه بر ویژگیهای سادهای مانند رنگها و لبهها تمرکز دارند. با پیشرفت دادههای تصویر در لایههای CNN، این شبکه شروع به تشخیص عناصر یا اشکال بزرگتر میکند تا اینکه در نهایت شیء مورد نظر را شناسایی کند.
CNNها با عملکرد برترشان در ورودیهای تصویر، گفتار یا سیگنال صوتی از سایر شبکههای عصبی متمایز میشوند. قبل از CNN ها فرایند تشخیص تصویر بسیار زمان بر بود ولی اکنون رویکردی مقیاس پذیرتر برای طبقه بندی تصویر و تشخیص اشیا ارائه میدهند و دادههای با ابعاد بالا را پردازش میکنند.
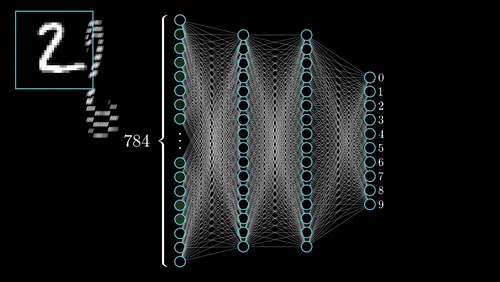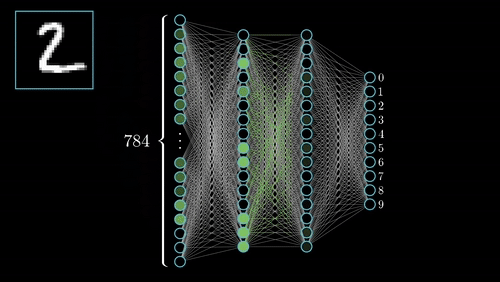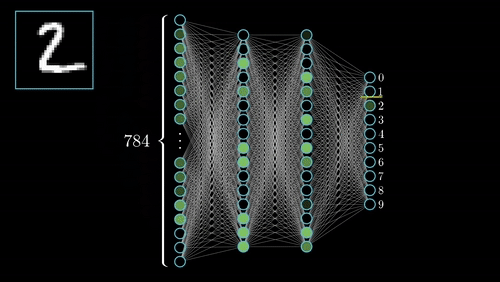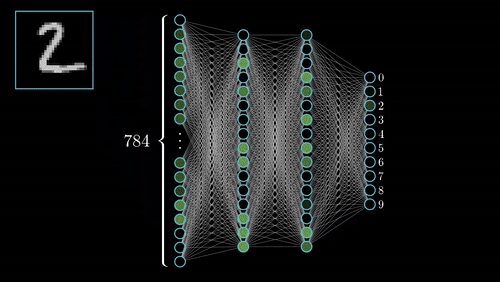
عیب اصلی CNN ها در بالا بودن هزینه های تجهییز و نگه داری آن هاست چرا که این محاسبات نیاز به GPU های قدرتمند است که بسیار گران هستند .
رمزگذار های خودکار (Auto encoders)
یادگیری عمیق به کمک تحلیل تصویر و صدا و سایر داده های پیچیده توانسته است که پا را فراتر از تحلیل داده های عددی بگذارد.
یکی از اولین مدل هایی که توانست به این هدف برسد “رمزگذار خودکار متغیر” بود. این مدل جز اولین هایی بود که در زمینه تشخیص صدا و تصاویر حقیقی مورد استفاده قرار گرفت. با آسان تر کردن مقیاس بندی در فرایند مدل سازی به مرور توانست مدل سازی عمیق مولد را ایجاد کند که سنگ بنای چیزی است که امروزه ما به عنوان هوش مصنوعی مولد میشناسیم.
رمزگذارهای خودکار از بلوکهای رمزگذار و رمزگشا ساخته شدهاند، معماری ای که زیربنای مدلهای زبانی بزرگ امروزی نیز هست. کد گذار ها مجموعه داده را به حالت نمایشی فشرده و متراکم تبدیل میکنند و داده های مشابه را نزدیک به هم قرار میدهند. آنها از این فضا نمونه برداری میکنند تا ضمن حفظ مهم ترین ویژگی های مجموعه دادهها، چیز جدیدی را نیز ایجاد کنند.
مهم ترین مزیت کدگذار های خودکار در این است که میتوانند حجم بسیار زیادی از داده را بگیرند ولی به صورت بسیار فشرده آنها را نشان دهند بنا بر این مهم ترین ویژگی آنها امکان تشخیص ناهنجاری و انجام وظایف طبقه بندی داده هاست که در نهایت منجر به افزایش سرعت انتقال داده و کاهش فضای ذخیره سازی میشود. کدگذار های خود کار توانایی کار کردن بر روی داده های بی نام را دارند و در جایی که داده ها نام و برچسبی ندارند ، بیشتر استفاده میشوند.
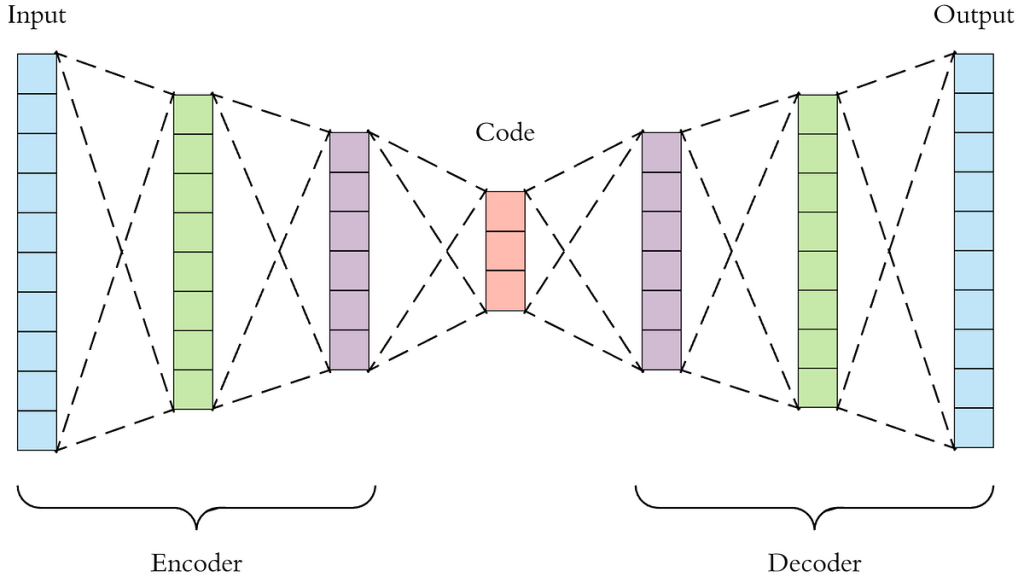
نقطع ضعف های کد گذار های خود کار :
آموزش ساختارهای عمیق میتواند منابع محاسباتی را به شدت مصرف کند. در طول عملیات بدون نظارت، مدل ممکن است ویژگیهای مورد نیاز را نادیده بگیرند و در عوض به سادگی داده های ورودی را تکرار کنند.همچنین ممکن است پیوندهای پیچیده ی داده ای را در مجموعه دادههای ساختار یافته نادیده بگیرند و نتوانند روابط آنها به یک دیگر را شناسایی کنند.




سپاس از مطلب آموزنده و عالی🙏🙏😇😇
ممنون از نگاه شما